チリン
最近あったかいねーってことで夜出てきましたひさびさに。
心拍計動いてなかった(^^;
せっかくなので、GPSロガーをジャケットの右ポケットに無造作に入れて、どんくらいログ取れるか試してみた。
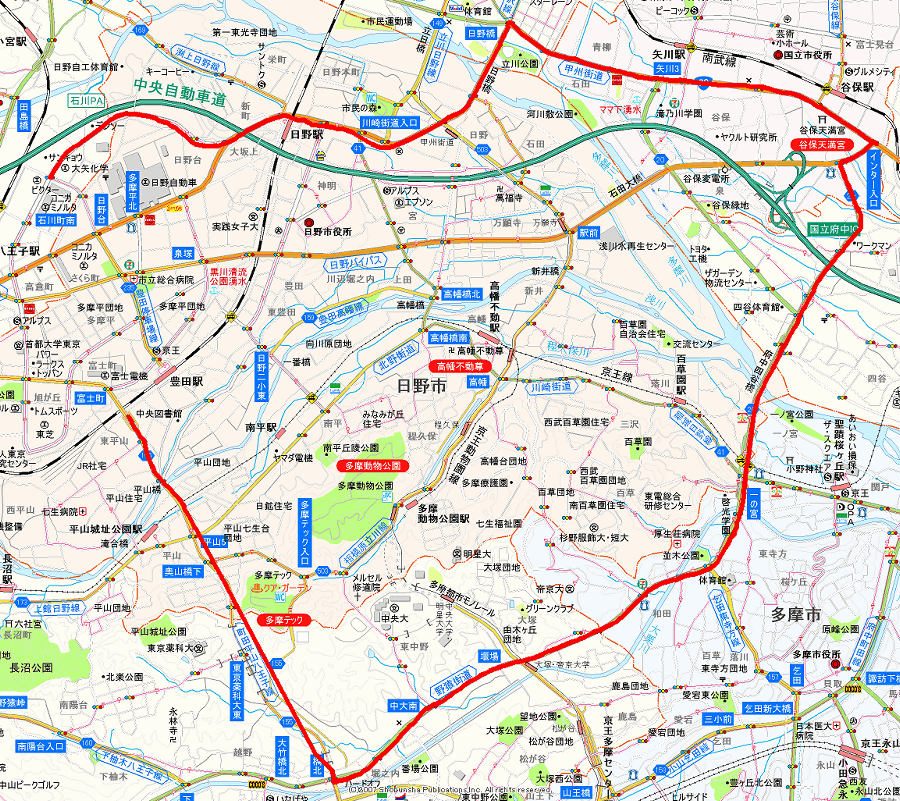
右ポケットとはいうものの、走行中はほぼ体の下に入ってしまうのでどうかなと思ったんですがまずまずの成績って感じですか。
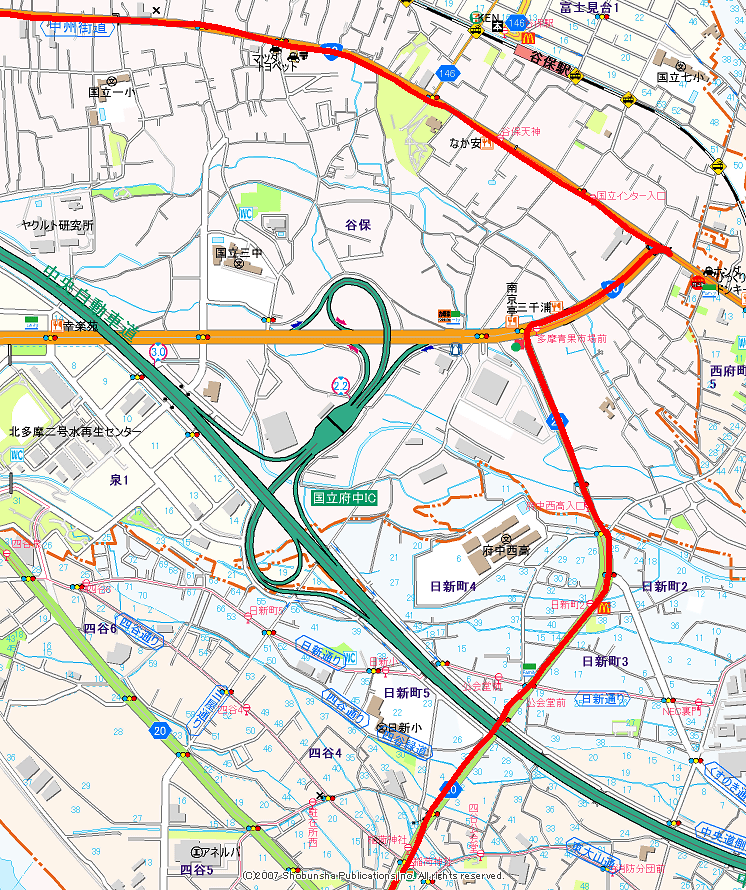
左上から来て、20号を右折するときに、一旦T字路を通り過ぎてちょっと戻ってくるんですが、そこも一応記録できてますね。
ちゃんとハンドルバーの上とかに取り付ければ結構な精度が期待できそうです。
しかし最近CSVに保存された過去のデータをローカルDBにインポートする作業をしこしことやってるのですが、そのためのツールをC#で書いてたりします。
エクスポートされたCSVには、一応の命名規則が付けて保存されているので、
「ホニャララ_200603.csv」とか「カッパスリッパ_200512.csv」とか「安達酒店_200702.csv」みたいな感じ。
でまぁズボラな私としては、Windowsアプリにして、ダイアログ上にリストボックスを一個作って、そこへ適当にドロップするとファイル名から勝手に判断して各々のテーブルに保存していってくれるというものを作っちゃえば、ぽいぽいっとファイルドロップして帰っちゃえば何日かでインポート終わるな。
というもくろみで作り始め。
なにしろcsvはいっぱいあるし、トータルで2000万レコードを超えそうなので楽に出来るようにしないとへこたれちゃうのです。
エクスポートされたcsvにはカラム(キー)情報がさっぱりなかったので、DBのテーブルに、そのCSVの何カラム目のデータをテーブルに入れるか、というのを洗い出し。
で、情報としてひとまとめにしたいのは、
「何というファイル名のcsv」が、「どのテーブル」に、「どのカラムをテーブルのどこに」入れるか。
ってことなので、それはそのままオブジェクト配列に入れとくことに。
たとえば、「ホニャララ_xxxx.csv」は「TABLE_HONYA」へ入れる。CSVのカラム 2,5,8,20,1の順番にテーブルへ格納。とか決めて、
object[][] objarr = new object[3][]; とか用意。
で、
objarr[0] = new object[] { “ホニャララ”, “TABLE_HONYA”, new int[] {2,5,8,20,1}};
って感じ。
同様に、
objarr[1] = new object[] { “安達酒店”, “TABLE_ADACHI”, new int[] {5,3,8,2,1,20,21}};
みたいにすると。おぶじぇくと配列便利。
こーしておけば、listboxに入っているファイル名を列挙してきてそれがfilenameという変数に入っているとすると、filename.IndexOf((string)objarr[i][0]) みたいにチェックしてどのテーブルと規則を使えばいいかわかると。
問題は、テーブルに入れるデータとして、他のCSVから持ってこないといけない場合があって、しょうがないのでそういうテーブルは最後にインポートすることにして、すでにDBに入ってるものからselectしてくることに。これをどうしようかと思ったけど、暫定処置として、
objarr[2] = new object[] { “カッパスリッパ”, “TABLE_HIROKAWA”, new int[] {2,3,6,-1,-2,5,6}};
みたいに、intの配列中にマイナスを持たせて、また別にselect専用の文字配列を作って
string[] optsql = new string[]{ “select a from TABLE_ADACHI where b='{0}’!5”, ・・・};
みたいにしておいて、int配列がマイナスの場合には、
string[] sqlst = optsql[(-1を0にする式)].split(‘!’); とかやったあと、
querystr = db.ExecuteScalar(string.format(sqlst[0], csvdata[int.parse(sqlst[1])]));
みたいにして目的の値を得る。みたいな苦肉の策。
デリミタとして!が適切かどうかは無視(^^;
別配列用意するのもなんかエレガントじゃないので、intの配列やめてstringかobjectにしてその配列中にSQL入れちゃってもいいかもね。
今回は1回しか使わないヤッツケ仕事なのでそのへんはいいかげんに。
ところで当初、autocommit on のまま気づかずinsertしてたので、40レコード/秒くらいしかインポート出来なかったのね。
おっせえ!
で、いろいろちゅーにんぐです。autocommit offにして、start transactionして1000レコードinsertしてcommit。 それだけでも200~300レコード/秒くらいにはなったのですが、でも遅い。
CSVファイルはたくさんあって、元々のDB内でキーは一意になっていたはずなのですが、なぜか複数のCSVで同じキーを持つレコードがある・・・たぶんCSVには毎月落としていたようなので、エクスポートするときの日付が重なっていたりしたものだと思われるので、少々乱暴な気もするけどたぶんOKってことで、Insertして一意制約違反が出ても無視。というポリシーでやっていました。
ところで、MySQLにはマルチプルインサートという技もあって、たとえば
create table kuroneko (
a int primary key,
b int );
なんて作ったテーブルに対して、
insert kuroneko values (1,0), (2,10), (3,100) ・・・
等として一気に何レコードもインサート可能ということらしい。
ところが、何レコードもインサートするSQLを書いても、そのうち1レコードでも一意制約違反があるとそのSQLは破棄されちゃうのですよ。
しかも複数の一意制約違反があっても、エラー文字列として返されるのは最初の違反に関するものだけ。
コレは・・・
でもめげずにこれを使ってやってみた。
100レコードのマルチプルインサートSQLを作ってどんどんインサートしていくと、500~1000レコード/秒になる。えらい速度が出ます。
でも、一意制約違反が出たときはそのSQL中に書いてあるレコードを1レコードずつインサートし直し・・・
そこのオーバーヘッドがでかくて、結果1レコードずつ入れるのとあんまり変わらん・・・・
で、更に調べると、MySQLには一意制約違反が出ても、更新処理として値を書き込める技もあるようで。いわく、ON DUPLICATE KEY UPDATE
insert kuroneko values (1,2,3) ON DUPLICATE KEY UPDATE c=c+1
のように、あちこちで書いてある。
要するにインサートしようとしたときにすでに同じキーのレコードがあった場合に、元の値と今回の値を合算するとか、元の値をインクリメントするとかいう目的に使えるということ。
今回はエラーをすっとばすという目的(わらい なので、
insert kuroneko values (1,2),(2,4),(5,8),・・・ on duplicate key update a=a
なんて書いて、同じキーがあったら a=a という無意味な式を実行。ということにしてみた。
結果、マルチプルインサートでもエラー全無視でインサート出来て500~1000レコード/秒コンスタントになってよかったよかった。それ以上の速度はHDDの問題でもう無理ぽいです。
まぁ一意制約違反無視なんてケースはそうないだろうけど(^^;